SQL Server Database Filegroups
Jan 27, 2024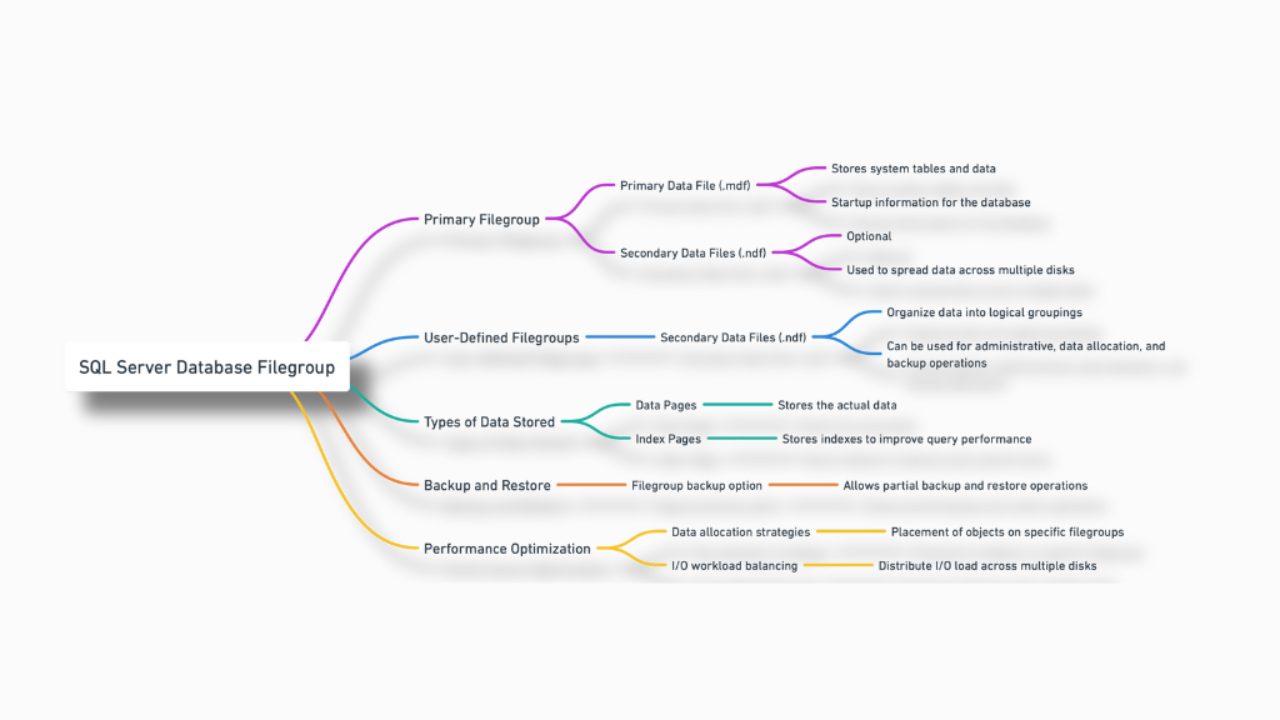
Edition: Saturday, January 27th, 2024
Welcome to this week's edition. We'll break down the two most popular posts ranked by comments. Be sure to grab the scripts to work through the demo yourself if you'd like. We'll jump right in (I hear DBAs are busy people).
Day 24 - Comments 24
Let's look at the first challenge. I've encountered this one a few times. It's essential to know how to identify where tables and indexes reside within a SQL Server database. Check out the comments on the post above for some script examples. Before we dive in, here is a quick overview of filegroups.
What is a filegroup?
In SQL Server, a filegroup is a logical grouping of one or more physical data files in a database.
Types of Filegroups:
- Primary Filegroup: This contains the primary data file (
.mdf) and any secondary files not explicitly assigned to another filegroup. All system tables are stored in the primary filegroup. - Secondary Filegroups: These are user-defined filegroups that can contain one or more secondary data files (
.ndf). They are useful for organizing data across multiple disks or for administrative purposes. - Memory-Optimized Data Filegroup: This type of filegroup stores memory-optimized tables. These filegroups contain checkpoint files for memory-optimized tables and are required for the In-Memory OLTP feature. Once this filegroup is created, it can only be removed by dropping the database.
-
FileStream Filegroup: Introduced to store unstructured data (like documents, images, etc.) more efficiently, This type of filegroup allows large objects to be stored in the file system while maintaining transactional consistency and integration with SQL Server.
Benefits of Using Filegroups
Filegroups simplify the administration of SQL Server databases, especially when managing and optimizing data storage.
- Data Organization: Filegroups can help organize data within the database by allowing you to group data files logically.
- Improved Performance: Placing filegroups on separate disks can improve database performance by distributing I/O load. However, those disks could all reside on the same physical storage array. This layer is typically obfuscated from the DBA's view. When considering multiple filegroups or storage in general, it's essential to work with the storage administrator to outline expectations. Here are a few questions I'd start with:
- What are the expected IOPS the drive will support?
- What is the expected throughput the drive will support?
- How many physical disks can be lost before impacting the drive's availability?
- Are multiple paths defined to the storage array from the server hosting SQL Server?
- Backup and Restore: Filegroups allow for more flexible backup and restore options. You can backup or restore individual filegroups, particularly useful for large databases. Check out Piecemeal Restores as an example.
- Data Allocation: When creating database objects, you can specify which filegroup they should reside in, allowing for better control over where data is stored.
Now, back to the question. How can you identify what objects are hosted in the INDEXES filegroup?
You can use a combination of system views to identify where each table and index resides.
-
sys.indexes: This view provides information about all indexes in the database, including those on tables and views.
-
sys.filegroups: This view gives information about the filegroups in a SQL Server database.
-
sys.objects: This view contains a row for each object created within a database, such as tables, views, stored procedures, etc. It's essential for obtaining metadata about these objects, such as their names, types, creation dates, and modification dates.
- sys.partitions: This view provides detailed information about the partitions of tables and indexes within the database.
Here's a script I'll usually begin with.
For more script examples, check out the comments section on the original post. Jeff Moden, provided an alternative script that returns additional information (SizeMB and Row count). We'll save how to move these objects for another day.
Demo
Here's the script I used and a quick video you can use to set up an example scenario in your sandbox. Scripts are courtesy of ChatGPT with some minor tweaking.
Script to create the demo database - Filegroup_Demo

Video - Youtube
Day 25 - Comments 13
This is a common scenario when hosting applications and SQL Server together. If you encounter this situation and users are complaining, first identify what is consuming the CPU resources during the time users are being impacted. Windows has multiple methods for reviewing CPU stats in real time:
- Task Manager
- Resource Manager
- Performance Monitor
- Powershell
These are great if you can actively monitor the issue. However, as luck would have it, the problem occurs while you're out of the office. We can use Perfmon and define a Data Collector Set for this scenario.
Example data collector set
Below is a screenshot of a data collector set with one performance counter. It collects % Processor Time for all processes running at the time of collection. Sample refresh can be adjusted based on how granular you'd like the collection.

To see the results, review the Reports. In this example, CPU load was generated using both t-sql and Powershell. Powershell represents the "other" application in this case.

Expanding CPU --> Process provides detailed information regarding CPU % usage by process. In the case above, Powershell was using a combined percentage of 76%, while SQL Server was only using 18%.
If you don't have another monitoring tool, this is a built-in tool you can use to gain clarity on resource utilization. Check out the links below for more information on how to set up a data collector and how to schedule it. Give it a try in your lab / sandbox environment.
Create Data Collector for Performance Counters - Business Central | Microsoft Learn
Schedule Data Collection in Windows Performance Monitor | Microsoft Learn
Conclusion
That's it for this week. Thanks for reading! You can catch the daily challenges on LinkedIn.
Get free access to my "SQL Server Automation: Your First Steps with Ansible" Guide
Get started with Ansible using this free guide. You'll discover how simple Ansible is to use, understand core concepts, and create two simple playbook examples.
When you signup, we'll send you periodic emails with additional free content.